서브쿼리
: 쿼리 안의 쿼리
* 서브쿼리 위치에 따른 구분
| 종류 | 서브쿼리가 들어가는 위치 |
| 스칼라 서브쿼리 | SELECT문의 칼럼 입력 위치 |
| 인라인 뷰 | FROM절의 테이블 입력 위치 |
| 중첩 서브쿼리 | WHERE절, HAVING절의 칼럼 똔느 테이블 입력 위치 |
- VIEW: 가상으로 동적인 테이블을 만든 것
* 메인쿼리의 사용 여부에 따른 구분 (중첩 서브쿼리의 종류임!)
- 서브쿼리에서는 메인쿼리를 참조(메인쿼리의 컬럼)할 수 있다.
| 종류 | 설명 |
| 연관 서브쿼리 | 메인쿼리의 칼럼을 서브쿼리에서 사용 |
| 비연관 서브쿼리 | 메인쿼리의 칼럼을 서브쿼리에서 사용하지 않음 |
중첩 서브쿼리
: 쿼리 안, 특히 WHERE절과 HAVING절에 다른 쿼리가 중첩되어 들어간 경우를 지칭
- 반환하는 값의 형태가 하나가 아니며, 다양한 반환값을 지님
| 반환값 유형 | 설명 |
| 단일행(Single Row) | - 반환되는 값이 단일행, 1건 이하의 데이터인 경우 - 단일행 비교연산자 ( >, >=, <, <=, =, <> 등) |
| 다중행(Multi Row) | - 반환되는 값이 다중행 - 다중행 비교연산자 ( IN, ALL, ANY, SOME, EXISTS 등) - 다중행 연산 ( <=> 단일행 복합 연산이라고 생각) |
| 다중칼럼(Multi Column) | - 반환되는 값이 여러 칼럼, 벡터인 경우 - 반환값이 단일 칼럼인 스칼라 서브쿼리와 달리 반환값이 여러 칼럼을 가진 테이블 형태 |
그룹 함수
- GROUP BY절의 연산 결과에 대해 그룹 별로 연산을 수행하는 함수
- 집계함수, ROLLUP, CUBE, GROUPING SETS 등
- 그룹별 소계, 전체 총계(전체의 합)
ROLLUP(1차원적, 평면적)
: GROUP BY절에 들어가는 칼럼을 대상으로 하위 그룹핑을 수행
* 맨 처음 명시한 컬럼에 대해서만 소그룹 합계를 구함
- 그룹별 소계 & 총계
ex) GROUP BY ROLLUP(날짜, 이름) -- (날짜, 이름) -> (날짜) -> (전체) 순서로 하위 그룹핑
SELECT CYL, COUNT(*)
FROM MTCARS
GROUP BY ROLLUP(CYL)
ORDER BY CYL;
# CYL 수별로 그룹핑하여 그룹별 개수를 구하고, 총계를 구한다.
CUBE(다차원적)
: 조합 가능한 모든 경우로 그룹핑을 수행
* GROUP BY절에 명시한 모든 컬럼에 대해 소그룹 합계를 계산
ex) GROUP BY CUBE(날짜, 이름) -- (날짜, 이름) -> (날짜) -> (이름) -> (전체) 순서로 하위 그룹핑
SELECT CYL, GEAR, COUNT(*)
FROM MTCARS GROUP BY CUBE(CYL, GEAR)
ORDER BY CYL, GEAR;
# 실린더 수, 기어 수 별로 그룹핑하여 그룹별 개수를 구하고,
# 실린더 수별 소계, 기어 수별 소계, 총계를 구한다.
GROUPING SETS
: 그룹핑 대상을 지정하는 함수
- GROUPING SETS의 인자에 ROLLUP이나 CUBE 함수를 넣을 수 있으며, 이런 경우 ROLLUP이나 CUBE의 그룹핑 결과인 소계, 총계들이 각각 별개의 인자로 지정된 것과 같은 결과를 반환
SELECT CYL, GEAR, COUNT(*)
FROM MTCARS
GROUP BY GROUPING SETS(CYL, GEAR)
ORDER BY CYL, GEAR;
# 실린더 수, 기어 수 별로 그룹핑하여 그룹 별 개수를 구한다.
* 알아둘 것 (ROLLUP, CUBE 코드 구분하는 문제 출제 비중 높음)
1. ROLLUP -> GROUPING SETS으로 표현하는 방법
ROLLUP(CYL, GEAR)
GROUPING SETS((CYL, GEAR), (CYL), ())
# GROUPING SETS에서 전체는 빈 괄호 = ()
2. CUBE -> GROUPING SETS으로 표현하는 방법
CUBE(CYL, GEAR)
GROUPING SETS((CYL, GEAR), (CYL), (GEAR), ())
GROUPING
: ROLLUP, CUBE, GROUPING SETS과 함께 사용하여 소계에 해당하는 결과 행과 그렇지 않은 행을 구분
- 소계에 해당하는 결과 행의 경우에는 1을 반환하고 그렇지 않은 경우에는 0을 반환
- GROUPING 함수와 CASE문을 사용하여 소계나 총계를 표시하는 행에 대해서 그 의미에 맞는 텍스트 값으로 지정 가능
* 반드시 CASE와 함께 나옴
SELECT CASE GROUPING(CYL)
WHEN 1 THEN '총계' ELSE TO_CHAR(CYL) # 1일 경우 총계, 다른 경우 CYL
END AS CYL,
COUNT(*)
FROM MTCARS
GROUP BY ROLLUP(CYL) # CYL로 그룹핑 -> 0을 반환, 전체로 그룹핑 -> 1을 반환
ORDER BY CYL;
- NULL 부분을 총계라고 텍스트를 채우고 싶다. > 그룹하는 행에 대해 구분할 수 있어야 한다. > 그게 GROUPING

(1) 실행되면, 총계 텍스트 위치에 NULL로 표현된다.
(2) 총계라는 텍스트를 출력하고 싶으면, 1일 때 총계, 다른 값일 때 총계와 type을 맞춰준다. (컬럼은 type이 같아야 함)
윈도우 함수
순위함수 -> OVER절에 들어가는 ORDER BY
집계함수 -> OVER절에 들어가는 PARTITION BY
순위 함수
| 함수 이름 | 설명 | 예 |
| RANK | - 동일한 순위는 같은 순위값을 가진다. - 순위값은 앞 순위까지의 누적 개수 + 1 이 된다. |
1, 2, 2, 4, 4, 4, 4, 7 |
| DENSE_RANK | - 동일 순위는 같은 순위값을 가진다. - 순위값은 단순하게 앞 순위 + 1 이다. |
1, 2, 2, 3, 3, 3, 4 |
| ROW_NUMBER | - 동일 순위라도 각각의 행이 고유의 순위값을 가진다. | 1, 2, 3, 4, 5, 6, 7 |

OVER절을 가지고 RANK()를 매긴다.


집계함수
| 함수 이름 | 설명 |
| COUNT | 값이 Null인 행을 제외한 행의 개수를 파티션 별로 집계하거나 누적 집계를 계산하여 반환한다. |
| SUM | 입력된 칼럼에 대해 파티션 별 합계를 구하거나 누적 합계를 계산하여 반환한다. |
| AVG | 입력된 칼럼에 대해 파티션 별 평균을 구하거나 누적 평균을 계산하여 반환한다. |
| MIN | 입력된 칼럼에 대해 파티션 별 최솟값을 반환한다. |
| MAX | 입력된 칼럼에 대해 파티션 별 최댓값을 반환한다. |

Top N 쿼리
ROWNUM
- 현재 저장된 데이터를 그대로 두면서 각 행에 순차적인 번호를 부여(순회하면서!)
- 테이블의 첫 행부터 차례로 순회하면서 값을 반환하기 때문에 중간을 건너뛰고 값을 가져올 수 없으며,
- WHERE절에 ROWNUM을 사용할 경우 조건식이 FALSE가 되면 순회를 멈추고 결과를 반환함에 주의

* WHERE ROWNUM = 5 인 경우, 아무 것도 출력하지 않음
* ORDER BY 이전에 ROWNUM이 정해짐 > ORDER BY 하고 나면 순서 섞음 => 정렬을 서브 쿼리로 사용
Top N 쿼리
* RANK, DENSE_RANK, ROW_NUMBER 차이점 알아두기 (등수는 같으나 출력되는 건수가 달라질 수 있다. )

계층형 질의와 셀프 조인
# 계층형 질의
SELECT *
FROM EMP
# 루트 노드 설정
START WITH MGRNO IS NULL
# 부모-자식 관계 설정
CONNECT BY PRIOR EMPNO=MGRNO
# 프자부순 - PRIOR 자식 부모 순방향 / 프부자역 - PRIOR 부모 자식 역방향
ORDER SIBLINGS BY EMPNO DESC;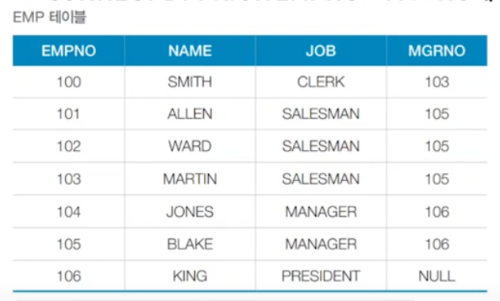
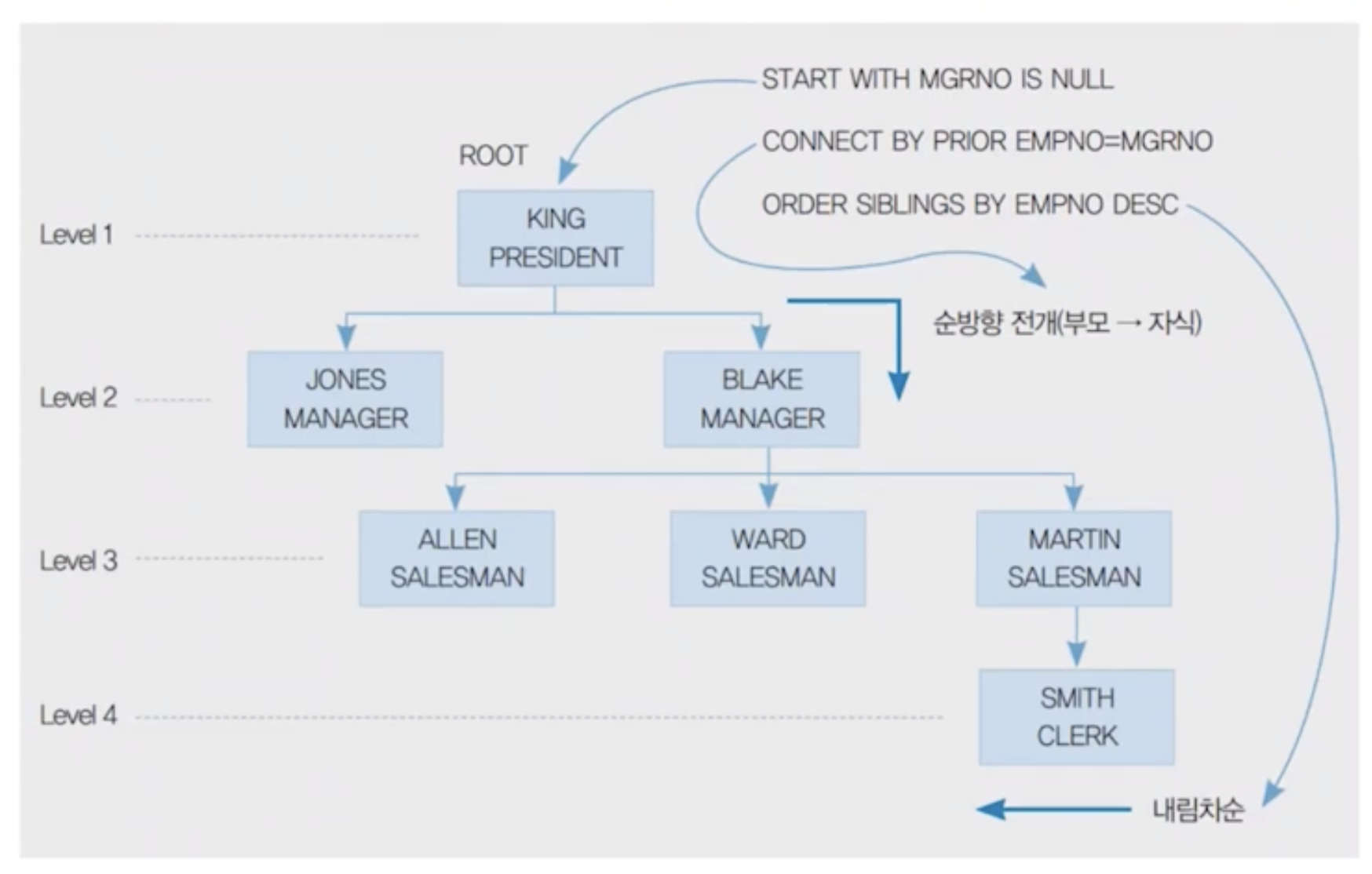
* KING > BLAKE > MARTIN > SMITH > WARD > ALLEN > JONES
부모 - 자식부터 체크, EMPNO 기준으로 내림차순
<계층형 질의 문제 푸는 순서>
1. 데이터를 보고 트리 구조를 먼저 그린다.
2. 루트 노드를 먼저 작성
3. 순방향, 역방향에 맞춰서 트리 그리기
PIVOT절과 UNPIVOT절 (2024년 시험 도입)
: 컬럼을 기준으로 여러 개의 행으로 나뉜 데이터를 행과 열을 전환해 테이블을 재구성하여 보기 편하도록 만드는 것
* 형태를 외워라!
* PIVOT
- 행을 열로 바꾼다. 지정된 칼럼의 각 행 속성값들이 새로운 칼럼 헤더가 되고 이에 맞게 전체 속성값들이 재배치된다.
- 내부적으로 첫 번째 칼럼에 대해서 GROUP BY 연산이 수행됨을 포함하고 있다.
- 값에 대해서 칼럼을 지정한다.
PIVOT _ FOR TABLE_NAME IN _* PIVOT을 하는 이유 ? 보고서를 쓰기 위해서
* UNPIVOT
- 열을 행으로 바꾼다. 칼럼 헤더들이 한 칼람의 각 행 속성값이 되고 이에 맞게 전체 속성값들이 재배치된다.
- 칼럼에 대해서 값을 지정
UNPIVOT _ FOR COLUMN_NAME IN _* UNPIVOT을 하는 이유? 통계치를 구하기 위해서

정규표현식 (2024 시험 도입)
1. 정규표현식 메타문자
- 문자 그 자신이 가진 의미가 아니라 다른 의미로 사용되는 문자
ex) 정규표현식에서 '^' 문자는 '^' 문자 그 자체가 아닌 입력 문자열의 시작을 의미
2. 정규표현식 리터럴 문자
- 문자 그 자체가 가진 의미 그대로 사용되는 문자로, 정규표현식에서 패턴 매칭을 수행할 때 처리되는 최소 단위
ex) 알파벳의 경우 'a', 'A', 한글의 경우에는 '가', '나' 등 한 음절의 한 개 문자
정규표현식: 1, 2 문자를 섞어서 문자열의 "형식"을 나타내는 것, 그 형식을 기준으로 해서 문자열의 특정 "패턴"을 찾는 것
주요 메타문자
| 메타 문자 | 의미 | 예 |
| ₩ | 메타 문자를 리터럴 문자로 표시하거나 리터럴 문자와 결합하여 정해진 메타 문자를 표시 |
₩₩: ₩ ₩n: 줄바꿈(개행) 문자 |
| ^ | 개행으로 나뉜 문자열의 시작 지점 | ^The: The로 시작하는 문자열 |
| $ | 개행으로 나뉜 문자열의 끝 지점 | ing$: ing로 끝나는 문자열 |
| . | 임의의 한 문자(개행 문자는 제외) | a.b: acb, a-b, a1b, ... |
| ? | 선행 문자 0 또는 1개 | no?: n, no |
| * | 선행 문자 0개 이상 | no*: n, no, noo, nooo, ... |
| + | 선행 문자 1개 이상 | no+: no, noo, nooo, ... |
| | | 선택적 일치 | a | b: a, b |
| [ ] | 대괄호 안의 문자들 중 하나와 일치 | [abc] : a, b, c |
| [-] | 연속 문자의 범위를 지정 | [a-z]: a부터 |
| [^] | 대괄호 안의 문자들을 제외한 나머지 문자들 중 하나와 일치 | [^abc]: d, e, z, ... (a, b, c를 제외한 나머지 문자) |
| ( ) | 소괄호로 묶인 표현식을 한 단위로 취급 | (ab): ab |
Oracle 정규표현식 함수 (Oracle 10g부터 지원)
| 정규표현식 함수 | 설명 |
| REGEXP_LIKE | 정규표현식을 사용한 LIKE 연산 |
| REGEXP_REPLACE | 정규표현식을 사용하여 문자열 대체 |
| REGEXP_INSTR | 정규표현식을 사용하여 문자열 검색 후 위치 반환 |
| REGEXP_COUNT | 정규표현식을 사용하여 특정 패턴의 문자열 개수 반환 |
SQL Server 정규표현식 함수
- PATINDEX 함수: 찾고자 하는 문자열을 검색 후 위치를 반환, 정규식은 아니나 정규식과 유사한 패턴 문자열 지원
- LIKE 연산자: PATINDEX의 패턴 문자열 지원
| 메타 문자 | 의미 | 예 |
| % | 0개 이상의 문자 | %a%: a가 포함되어 있는 문자열 모두 |
| _ | 임의의 한 문자 | a_b: acb, a-b, a1b, ... |
| [ ] | 대괄호 안의 문자들 중 하나와 일치 | [abc]: a, b, c |
| [-] | 연속 문자의 범위를 지정 | [a-z]: a부터 z까지 소문자 알파벳 문자 |
| [^] | 대괄호 안의 문자들을 제외한 나머지 중 하나와 일치 | [^a-z]: a부터 z까지 소문자 알파벳을 제외한 나머지 문자 |
References
'🏆 자격증 > SQLD' 카테고리의 다른 글
| [SQLD 총정리] 1과목 1장 데이터 모델링의 이해 (0) | 2024.08.23 |
|---|---|
| [SQLD 총정리] 2과목 3장 관리 구문 (0) | 2024.08.22 |
| [SQLD 총정리] 2과목 1장 SQL 기본 (0) | 2024.08.22 |
| [과목 2] 1장 SQL 기본 (0) | 2024.08.19 |
| [과목 1] 2장 데이터 모델과 성능 (0) | 2024.08.07 |